
Analysis of next-generation sequencing (NGS) data set is a huge challenge. It needs a systematic and intelligent approach to process the NGS data efficiently. AgriGenome has developed workflows and programs to analyze large-scale biological data sets, especially focused towards NGS. Our analysis process includes data quality assessment, comprehensive analysis, interpreting results, and communicating and presenting results to the customers in meaningful formats. The analysis process may also include development of algorithm for some special projects. Below is the list of various data analyses that can be performed at AgriGenome. For detailed description of some of the below analyses, please download our white paper: WhitePapers
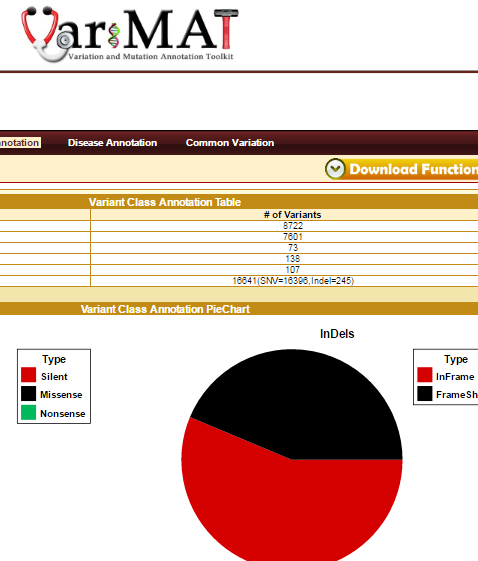
VariMAT is a web-based toolkit for comprehensive annotation of human single nucleotide variations (SNVs) and short insertions/deletions (indels). VariMAT utilizes different databases and public resources including UCSC, GENCODE, ENCODE, Ensembl, dbSNP, NCBI, HapMap, and the 1000-genomes project. The various annotation types implemented in the toolkit are: genomic, functional, common variation and disease annotation.
Genomic annotation includes genes, splice-sites, UTRs, repeats, conserved transcription factor binding sites (TFBS), regulatory regions (from ChiP-seq), conserved enhancers, CpG-Islands, miRNAs and promoter regions. Functional annotations implemented into the toolkit are variant class prediction (silent, missense, nonsense, inframe and frameshift), polyPhen and gene ontology summary.
Various disease annotations are included from OncoMD, GWAS, ClinVar, SNPedia. In addition, the tool also compares the variant with several published personal genomes and common variation databases – dbSNP, 1000-genomes, HapMap. It accepts input in variant call format (vcf) and 23andMe format. VariMAT is capable of annotating several thousand variants in minutes. It also generates several tables and plots that can be used for publications.

Designing primer for experimental validation is one most frequent tasks performed by a biologist. Primer designing involves several steps and is a time consuming process. PrimeMe is a web-based tool kit to simplify and speed up the primer designing process.
PrimeMe provides various search options including i) search by chromosome ii) search by gene/transcript iii) search by SNP. One can also upload a list of coordinates to design a primer. The current version of PrimeMe supports hg19 version of the human genome and uses RefSeq gene model to identify gene and transcript positions.
It also includes 5.5 million SNP coordinates from snp135 database. Users can design primer for either the complete gene region or exonic regions. While designing the primer, user can set primer conditions and primer type – PCR or Primer walking. The result for primer design is displayed in both graphical and tabular format with SNP, if any, being highlighted in the primer sequences. A link to the UCSC In-Silico PCR is provided to find the number of products the primer set would provide. One could also filter out the primers if a SNP is present in the first 3 bases in the primer 5' end. The complete result can be downloaded as a text file. Results can also be saved in the PrimeMe database for future use.
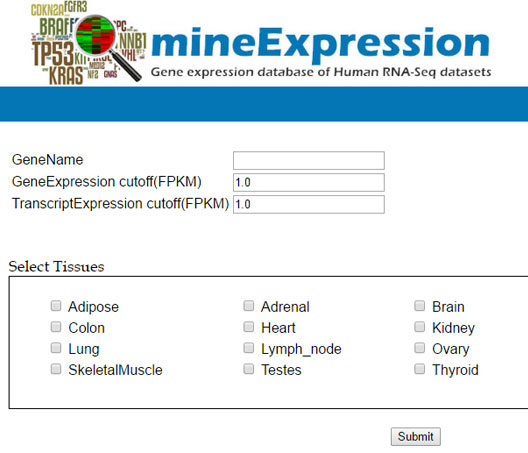
mineExpression is a database of gene and transcript expression for various tissues and cell lines. The RNA-seq datasets are downloaded from various public databases and are analyzed using custom RNA-seq pipeline at AgriGenome. The expression value estimated using our in-house pipeline is deposited into mineExpression database. A gene-based search is provided to extract expression value at gene and transcript level. User can select a cut-off value while searching and can also select one or more tissues/cell lines.

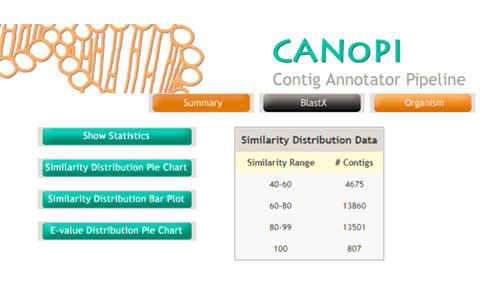
De Novo genome and transcriptome assembly generates several thousands of contigs. It is very important to perform comprehensive annotation of predicted genes and transcripts. The CANoPI annotation pipeline is designed to automate annotation of the contig with various databases. CANoPI results include BLASTX search result, similarity with known proteins at NCBI, Gene Ontology (GO) summary, UniProt annotation and species overlap summary. The pipeline generates several statistical charts and tables required for publication.
Analysis of next-generation sequencing (NGS) data set is a huge challenge. It needs a systematic and intelligent approach to process the NGS data efficiently. AgriGenome has developed workflows and programs to analyze large-scale biological data sets, especially focused towards NGS. Our analysis process includes data quality assessment, comprehensive analysis, interpreting results, and communicating and presenting results to the customers in meaningful formats.